Continue levering: bedrijfswaarde, voordelen, uitdagingen en statistieken
Continue levering verbetert de snelheid, productiviteit en duurzaamheid van ontwikkelingsteams.

Juni Mukherjee
Mede-auteur
Waarom continue levering?
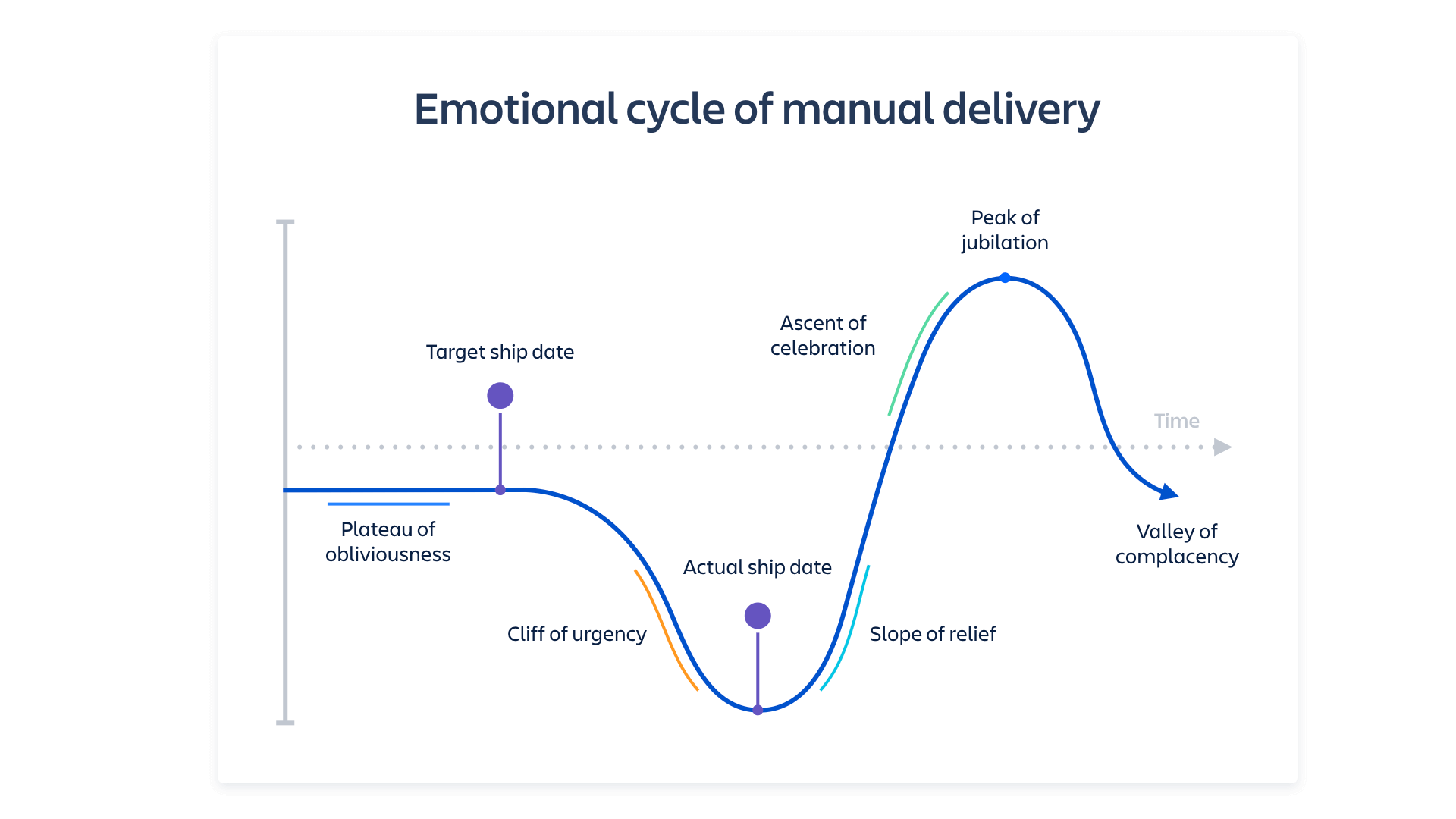
Welke emoties roept het woord 'release' bij je op? Opluchting? Opgetogenheid? Een geweldig gevoel van voldoening? Als nieuwe functies eindelijk beschikbaar zijn voor klanten en bugs zijn opgelost, is iedereen tevreden, toch? Nou, het duistere geheim in veel organisaties is dat het leveren van een release enorm veel moeite kost. Als je team nog steeds bezig is met handmatige tests om je voor te bereiden op releases en met handmatige of semi-gescripte implementaties om deze uit te voeren, liggen je gevoelens misschien meer in de buurt van 'angst' en 'verblindende woede'.
Daarom is softwareontwikkeling meer gericht op continuïteit, door middel van methodologieën zoals agile en DevOps. In het continue model worden kwaliteitsproducten regelmatig en voorspelbaar gereleased aan klanten. Daarom worden de ceremonie en het risico rond releases beperkt. Als je dagelijks afhankelijk bent van je pipelines, zul je de tekorten veel sneller opmerken (en oplossen!) dan als ze eens in de paar werken of maanden langskomen. Dat wil zeggen, maak het jezelf eenvoudiger door vaker productreleases uit te brengen. Een cultuur van continue verbetering is een DevOps-statistiek voor goed presterende teams.
De nadruk op continue levering, waaronder continue integratie, continue tests, constante monitoring en pijplijnanalyses, wijst allemaal op een algemene trend in de software-industrie: teams helpen te reageren op marktveranderingen. Vergis je niet. CD is niet het exclusieve domein van 'speciale' bedrijven en tech-lievelingen. Elk team, van de nederigste start-up tot de saaiste onderneming, kan en moet continue levering hebben.
In dit artikel wordt ingegaan op de business case om deze overstap te maken. Er wordt ingegaan op het werk dat nog voor ons ligt en de voordelen die dat zal opleveren voor het leveren van software via CD-pipelines.
Oplossing bekijken
Software bouwen en gebruiken met Open DevOps
Gerelateerd materiaal
De implementatiefrequentie meten
Belangrijkste zakelijke voordelen van continue levering
Continue levering verbetert de snelheid, productiviteit en duurzaamheid van softwareontwikkelingsteams.
1. Snelheid
Geautomatiseerde pipelines voor de softwarelevering helpen organisaties beter te reageren op veranderingen in de markt. De behoefte aan snelheid is van het grootste belang om de 'bewaartijd' van nieuwe functies te verkorten. Met een lage Time2Market hebben organisaties een betere kans om hun concurrentie te slim af te zijn en in bedrijf te blijven.
Onthoud dat snelheid op zichzelf geen statistiek is voor succes. Zonder kwaliteit is snelheid zinloos. Het heeft geen zin als pipelines voor continue levering foutieve code snel in productie sturen.

In de wereld van continue levering betekent snelheid dus verantwoorde snelheid, en niet suïcidale snelheid.
2. Productiviteit
Productiviteit vertaalt zich in geluk, en gelukkige teams zijn meer betrokken.
De productiviteit neemt toe wanneer saaie en repetitieve taken, zoals het invullen van een foutrapport voor elke ontdekte fout kunnen worden uitgevoerd door pipelines in plaats van door echte mensen. Zo kunnen teams zich concentreren op hun visie, terwijl pipelines het werkt doen. En wie wil het zware werk niet aan tools delegeren?
Teams onderzoeken issues die door hun pipelines zijn gemeld en zodra ze de oplossing hebben gevonden, worden de pipelines opnieuw uitgevoerd om te controleren of het probleem is opgelost en of er per ongeluk nieuwe problemen zijn ontstaan.

3. Duurzaamheid
Bedrijven willen marathons winnen, niet alleen sprints. We weten dat er doorzettingsvermogen nodig is om een voorsprong te hebben op de rest. Het kan nog moeilijker zijn om constant de rest voor te blijven. Het vergt discipline en nauwkeurigheid. 24/7 hard werken leidt tot voortijdige burn-outs. Werk in plaats daarvan slim en delegeer het repetitieve werk aan machines, die trouwens geen koffiepauzes nodig hebben en niet terugpraten!
Elke organisatie, of ze nu een technologiebedrijf is of niet, gebruikt technologie om zich te onderscheiden. Geautomatiseerde pipelines verminderen het handmatige werk en leiden uiteindelijk tot besparingen, aangezien personeel duurder is dan tools. De forse investeringen vooraf kunnen onervaren leiders zorgen baren, maar goed ontworpen pipelines stellen organisaties in staat om beter en sneller te innoveren om aan de behoeften van hun klanten te voldoen. CD biedt het bedrijf meer flexibiliteit in de manier waarop het functies en oplossingen biedt. Specifieke functiesets kunnen worden vrijgegeven aan specifieke klanten, of worden vrijgegeven aan een subgroep van klanten, om ervoor te zorgen dat ze functioneren en schaalbaar zijn zoals ze ontworpen zijn. Functies kunnen worden getest en ontwikkeld, maar ze blijven inactief in het product, waardoor er meerdere versies kunnen worden gebruikt. Wil je marketingafdeling een 'grote indruk maken' op het jaarlijkse branchecongres? Bij continue levering is dat niet alleen mogelijk, maar ook een triviaal verzoek.
Belangrijkste uitdagingen op het gebied van continue levering
Hoewel we er sterk van overtuigd zijn dat continue levering de juiste beslissing is, kan het voor organisaties een uitdaging zijn om veerkrachtige pipelines voor continue levering te ontwerpen en te bouwen. Omdat CD een grote herziening vergt in technische processen, operationele cultuur en organisatiedenken, kan het vaak lijken alsof er een grote hindernis is om aan de slag te gaan. Het feit dat daarvoor een forse investering nodig is in de infrastructuur voor softwarelevering van een bedrijf, die in de loop der jaren misschien verwaarloosd is, kan het een nog bitterdere pil maken.
Er zijn veel problemen waarmee organisaties worden geconfronteerd en de volgende drie zijn de meest voorkomende valkuilen: budget, mensen en prioriteit.
Budget: is dat van jou te laag?
De aanleg van pipelines voor continue levering vergt je beste mensen. Dit is geen bijproject waarvan de kosten onder het tapijt kunnen worden geschoven. Het verbaasde me altijd hoe sommige organisaties beginnen met het toewijzen van jonge leden en met bezuinigen op de aanschaf van moderne tools. Op een gegeven moment corrigeren ze hun traject en wijzen ze hun senior architecten toe om te werken aan het loskoppelen van de architectuur en veerkrachtige pipelines voor continue levering.
Maak geen te lage inschatting. Zet, op basis van je visie, een passend bedrag opzij om ervoor te zorgen dat de uitvoering ononderbroken verloopt. Lever een MVP (minimaal levensvatbaar product) voor continue levering en schaal dit vervolgens op in je hele organisatie.
Heb jij vooruitstrevende denkers?
Zelfs als je een budget hebt, kan de uitvoering uiteindelijk een menselijk probleem zijn.
Teams moeten zonder zorgen hun werkzaamheden automatiseren en doorgaan met nieuwe projecten. Als je mensen hebt die bang zijn voor geautomatiseerde agents die taken uitvoeren die ze anders handmatig zouden uitvoeren, dan heb je de verkeerde mensen in dienst.
Als je het gevoel hebt dat je vastzit, schakel dan naar een andere versnelling. Weet dat je je team een auto moet geven als ze alleen maar om een sneller paard hebben gevraagd! Begin snel met de hulp van ervaren kampioenen die je over deze eerste drempel heen zullen helpen. Mensen zijn tenslotte je grootste assets en train ze om de juiste dingen te doen. Maak het eenvoudig om het juiste te doen, en moeilijk om de verkeerde dingen te doen, en je zult aangenaam verrast zijn over het resultaat.
Gebrek aan prioriteit
"Laten we de lijn stoppen en pipelines voor continue levering bouwen!" zei geen enkele producteigenaar ooit.
Ter verdediging, ze zijn erop gericht de concurrentie voor te blijven met nieuwe functie die de wereld versteld doen staan. Tegelijkertijd weet je dat je een probleem hebt als in elke sprintplanner pipelines worden afgewogen tegen productkenmerken en worden ingeruild.
In sommige productbacklogs staan pipelines, als ze er al in voorkomen, onderaan de prioriteitenlijst. Kortzichtig leiderschap classificeert werk in verband met pipelines als kosten, in plaats van investeringen die de teams goed van pas komen. Ze ontkennen nog steeds welke schade ze op lange termijn aanrichten en helaas komen ze er soms mee weg.
Pipelines zijn hygiënisch. Als je in bedrijf wilt blijven, vraag jezelf dan af 'Is hygiëne belangrijk?'. Reken maar dat het zo is!
Statistieken voor continue levering
OLTP (online transactieverwerking) en OLAP (online analytische verwerking) zijn twee bekende technieken in de industrie. Beide concepten zijn van toepassing op pipelines voor continue levering en helpen bij het genereren van inzichten die organisaties in de juiste richting sturen. Laten we eens kijken hoe.
Pipelines bevatten enorm veel transactiegegevens
Stel je een typische dag voor in het leven van een softwareontwikkelteam. Het team commit een functie waaraan het bedrijf prioriteit geeft, commit tests voor die functie en integreert implementaties met de pipelines voor continue levering, zodat elke wijziging automatisch wordt geïmplementeerd. Het team realiseert zich dat de toepassing traag werd na de toevoeging van deze nieuwe functie, en bedenkt een oplossing voor het prestatieprobleem. Het team voegt ook prestatietests toe om er zeker van te zijn dat slechte reactietijden worden ontdekt voordat de aanvraag wordt gepromoot van testen naar stagen.
Zie elk van die commits als een transactie. En zo werken softwareontwikkelingsteams, de ene transactie na de andere, tot er een product ontstaat die de wereld versteld doen staan. En dan doen ze dat weer. Vermenigvuldig deze transacties tussen alle engineers en teams in je organisatie en je hebt vele transactiegegevens tot je beschikking.

Dit is een goede manier om door te gaan naar de volgende sectie over pipeline-analyses en hoe je het meeste uit die transactiegegevens kunt halen.
Laten we de transactiegegevens van de pipeline analyseren
Kunnen we de transactiegegevens analyseren om er extra informatie uit te trekken? Natuurlijk kunnen we dat!
Zoals bij alle transactiegegevens, zorgt het grote volume ervoor dat we het spoor bijster raken. Daarom moeten we aggregeren en analyses uitvoeren om inzicht te krijgen in onze organisatie. Analyses helpen ons om door het bos de bomen te zien, en hier zijn drie voorbeelden van hoe we onze praktijken hebben verbeterd op basis van pipeline-analyses en -inzichten.
Van de honderden implementaties die elke week plaatsvinden, kwamen we erachter dat het aantal mislukte implementaties van toepassing A driemaal zo hoog is als dat van toepassing B. Deze ontdekking bracht ons ertoe de ontwerpkeuzes van toepassing A op het gebied van de stabiliteit van de omgeving en configuratiebeheer te onderzoeken. We kwamen erachter dat het team slechte virtuele machines gebruikte in hun datacentrum om te implementeren, terwijl toepassing B in containers was geïnstalleerd. We gaven prioriteit aan een investering in onveranderlijke infrastructuur en kwamen na een maand terug om er zeker van te zijn dat het rendement van die investering goed was. En ja hoor, dat was het geval. Wat kan worden gemeten, kan worden opgelost.
Een ander voorbeeld is toen we erachter kwamen dat de fouten in de statische code-analyse van toepassing B de afgelopen kwartalen gestaag zijn gestegen. Dit zou kunnen betekenen dat het team achter toepassing B (opnieuw) opgeleid moet worden om betere code te schrijven. We hebben ook ontdekt dat de analysators voor statische code foutpositieven rapporteerden, wat betekent dat ze coderingsovertredingen hebben gesignaleerd terwijl die er niet waren. Dus hebben we hun analysators geüpgraded naar een bekende tool die standaard is in de industrie en het aantal foutpositieven is tot op zekere hoogte verminderd. We organiseerden een coderingsworkshop waar we de legitieme statische analysefouten hebben besproken en afgesloten. Tegen het einde ging het team weer vrolijk aan de slag.
Een ander interessant inzicht was dat de unittests van applicatie A minder codedekking hadden dan applicatie B en C, en toch had applicatie A het minste aantal productieproblemen in het afgelopen jaar. Het schrijven van unittests en het meten van de dekking van de code zijn prima. Die oefening overdrijven is niet productief voor het team en nutteloos voor de klanten. Les geleerd.
Key performance indicators (KPI's)
We kunnen niet op meningen vertrouwen om de organisatie in de juiste richting te sturen. Eerst moeten we KPI's definiëren op basis van hoe succes eruitziet. Ten tweede moeten we datagestuurde beslissingen nemen door KPI's te analyseren voor maanden, kwartalen en jaren.
Organisatorische KPI's vs. KPI's van afdelingen
Vaak hebben we individuele afdelingen hun eigen successtatistieken zien definiëren. Het is goed voor afdelingen om te begrijpen hoe succes er voor hen uitziet, zolang die statistieken maar aansluiten bij de doelstellingen van de organisatie.
Fouten bij tests vs. stagen vs productie
Enkele organisaties eisen dat ontwikkelaars eigenaar zijn van de testomgeving, dat QA eigenaar is van staging en Ops van productie. In plaats van dat ontwikkelaars worden overspoeld met codedekkingsrapporten voor unittests die in de testomgeving worden uitgevoerd, is het belangrijk dat ze een stap terug zetten en naar het totaalplaatje van alle omgevingen kijken, of ze die nu bezitten of niet.
Het percentage fouten in de staging als gevolg van prestatietests kan hoog zijn, en het kan te wijten zijn aan onjuiste prestatiebenchmarks of trage code. Een vergelijkende analyse zou kunnen aantonen dat pipelines het vaakst falen bij smoke-tests voor integratie in de productie, en dat zou een onderzoek waardig zijn. De hoofdoorzaak kan echte bugs in het product, een testcode met bugs, onjuiste configuratie van de tests, misverstanden tussen het product en de engineering zijn enzovoort.
Verder onderzoek zou kunnen uitwijzen dat er veel verkeerde testconfiguraties zijn, en je zou prioriteit kunnen geven aan het oplossen van die problemen om veelvoorkomende integratiefouten op te lossen. Bovendien is het ook in overeenstemming met het DevOps-model dat ontwikkelaars eigenaar zijn van hun code tot aan de productie.
Stabiliteitsindex
Als we eenmaal KPI's hebben gedefinieerd, is het voor ons van groot belang om te begrijpen of een KPI bias heeft en naar een bepaalde richting wordt gestuurd. Als dat zo is, moeten we deze in evenwicht brengen met andere KPI's die het zwaartepunt dichter bij het midden plaatsen. Eén zo'n KPI is stabiliteit.
Ontwikkelaars meten de stabiliteit met FeatureLeadTime, wat de tijd is die nodig is om een functie live te laten gaan in de productie. Een functie bestaat uit meerdere commits, en een meer gedetailleerde meting van FeatureLeadtime is CheckIn2GoLive, wat de tijd is die nodig is om een controle uit te voeren voordat de functie live gaat in de productie.
Meet CheckIn2GoLive via pipelines, aangezien dit kan worden geschat op basis van de tijd die een pipeline nodig heeft om code te promoten, van testen tot stagen tot productie. Daarnaast heeft CheckIn2GoLive ook rekening met MTTR-fouten (gemiddelde tijd tot oplossing) gehouden, aangezien de bugfix via dezelfde pipeline loopt, van test tot stagen en productie.
Interessant genoeg heeft snelheid, toen ik het aan Operations vroeg, vaak een negatieve connotatie, omdat ze worden gestimuleerd om risicomijdend te werken. Ze meten het aantal ontsnapte defecten om aan te geven dat er een storing is opgetreden, en ze definiëren stabiliteit aan de hand van het percentage defecten dat door de pipeline wordt opgevangen, in tegenstelling tot ontsnapte defecten.
Bedrijven definiëren stabiliteit aan de hand van klanttevredenheid of het aantal terugkerende klanten. Hoewel dit subjectief klinkt, kun je deze statistiek benaderen aan de hand van het aantal defecten dat door klanten naar voren is gebracht of aan de hand van enquêtes met feedback van klanten.
De stabiliteitsindex is een klassiek voorbeeld, waarbij Dev, Ops en Business vanuit hun eigen perspectief een mening hebben. De organisatie kan echter beter een mix creëren in plaats van er slechts op één te vertrouwen. Maak daarom een onpartijdige organisatie-index voor stabiliteit.
Kwaliteitsindex van de code
Een ander voorbeeld waarbij rekening moet worden gehouden met verschillende gezichtspunten is de kwaliteit van de code. Sommigen zeggen dat de kwaliteit van onze code wordt weerspiegeld door de dekking van de code, gemeten door middel van unittests, terwijl anderen zeggen dat het een cyclomatische complexiteit is. Standaard statische analysators melden duplicatie van code, beveiligingsproblemen en mogelijke geheugenlekken. Dit zijn allemaal echte maatstaven voor de kwaliteit van de code en vormen dus een index waarin al deze, en mogelijk andere, een rol spelen.
Zakelijke KPI's vs. technische KPI's
Een andere populaire KPI die organisaties graag in de gaten houden, is de waarde die in een sprint wordt geleverd. Een veelvoorkomende slechte gewoonte is om het aantal releases vast te leggen, wat op zichzelf geen waarde toevoegt. Je zou bits van punt A naar punt B kunnen verplaatsen zonder dat je bedrijf daar baat bij heeft en dat is niet goed genoeg. Sommige organisaties meten het aantal tests dat zojuist in die sprint is toegevoegd of het totale aantal uitgevoerde tests, en die geven ook geen bedrijfsresultaten weer, alleen technische inspanningen. De waarde die in een sprint wordt behaald, moet relevant zijn voor het bedrijf.
Een paar voorbeelden van zakelijke KPI's kunnen het aantal klantenacquisities in het laatste kwartaal en het aantal klikken op advertenties in de afgelopen maand zijn. Pipelines hebben geen directe invloed op deze bedrijfsstatistieken. De enige reden waarom we proberen zakelijke KPI's toe te wijzen aan technische KPI's is om inzicht te krijgen in de relatie tussen technisch werkzaamheden en bedrijfsdoelen.
Zakelijke KPI's die toegewezen zijn aan pipelines kunnen ons ook helpen om de ROI (return on investment, rendement) van pipelines te berekenen. Managementteams gebruiken deze statistieken om inzicht te krijgen in mogelijke verbeterpunten en om te plannen op basis van het budget.
Jouw traject starten
Verspil geen tijd met discussiëren over de vraag of continue levering geschikt is voor jou, of continue integratie voldoende is, of dat continue implementatie je redding is. Als je aan dit traject begint, biedt dit je team veel mogelijkheden om zich voortdurend te verbeteren! Je teams kunnen zorgeloos experimenteren en ze raken niet oververmoeid door na werktijd nog door te moeten gaan.
Leer hoe je een pipeline voor continue integratie, levering en implementatie (CI/CD) bouwt met onze DevOps CI/CD-tutorials. Bovendien biedt Open DevOps van Atlassian een open toolchain-platform waarmee je een CD-gebaseerde ontwikkelingspipeline kunt bouwen met je favoriete tools.

Deel dit artikel
Volgend onderwerp
Aanbevolen artikelen
Bookmark deze resources voor meer informatie over soorten DevOps-teams of voor voortdurende updates over DevOps bij Atlassian.

DevOps-community

Blog lezen